Lecture 4 ¶
0. 数据类型回顾 ¶
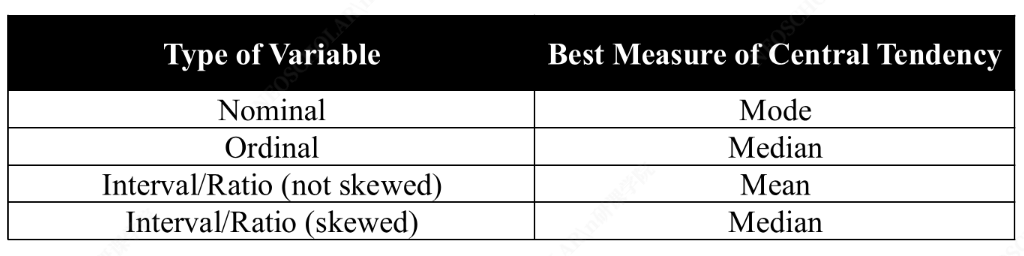
参数有:Ratio(比例)、Interval(区间)、Ordinal(序数)、Nominal(名义)。
| 类型 | 有序 | 有零点 | 可加减 | 可乘除 | 示例 |
|---|---|---|---|---|---|
| Nominal(名义) |  |
— | |
|
性别、血型 |
| Ordinal(序数) |  |
— | |
|
教育程度、满意度 |
| Interval(区间) | |
|
|
|
温度(摄氏)、日期 |
| Ratio(比例) | |
|
|
|
身高、体重、收入 |
1. Quantitative Data ¶
描述性统计(Descriptive Statistics) 是数据分析的基础,用于概括和描述数据的基本特征,不涉及对总体的推断。
1.1 集中趋势(Central Tendency)¶
集中趋势反映数据向某个中心值靠拢的程度。
均值(Mean)¶
算术平均值,是最常用的集中趋势度量:
- 优点:利用了所有数据的信息
- 缺点:对异常值(outlier)非常敏感
| Python | |
|---|---|
中位数(Median)¶
将数据排序后位于正中间的值:
- 优点:对异常值具有 鲁棒性
- 缺点:没有利用所有数据点的信息
众数(Mode)¶
数据中出现频率最高的值。一个数据集可以有多个众数(多峰分布)或没有众数。
| Python | |
|---|---|
均值 vs 中位数 vs 众数
- 正态分布:三者相等
- 右偏分布:均值 > 中位数 > 众数
- 左偏分布:众数 > 中位数 > 均值
偏态分布中,中位数 比均值更能代表"典型"值。
1.2 离散程度(Dispersion)¶
离散程度反映数据分布的 spread 或 variability。
极差(Range)¶
简单直观,但仅使用了两个极端值,容易受异常值影响。
方差(Variance)与标准差(Standard Deviation)¶
方差衡量数据点偏离均值的平均程度:
标准差是方差的平方根,与原始数据同量纲:
为什么除以 \(n-1\) 而不是 \(n\)?
当用样本估计总体方差时,除以 \(n-1\) 是为了得到 无偏估计(Bessel 校正)。这是因为样本均值 \(\bar{x}\) 本身是从数据估计出来的,损失了一个自由度。
四分位距(Interquartile Range, IQR)¶
其中 \(Q_1\) 是第 25 百分位数,\(Q_3\) 是第 75 百分位数。IQR 对异常值具有鲁棒性,常用于 箱线图(Box Plot) 和异常值检测。
| Python | |
|---|---|
变异系数(Coefficient of Variation, CV)¶
变异系数是无量纲的相对指标,适用于比较不同量纲或不同均值的数据集的离散程度。
1.3 分布形态(Distribution Shape)¶
偏度(Skewness)¶
偏度衡量数据分布的 对称性:
| 偏度值 | 含义 | 分布形态 |
|---|---|---|
| = 0 | 完全对称 | 正态分布 |
| > 0 | 右偏(正偏) | 尾部向右延伸 |
| < 0 | 左偏(负偏) | 尾部向左延伸 |
峰度(Kurtosis)¶
峰度衡量数据分布的 尾部厚度(与正态分布相比):
(以上为 excess kurtosis,正态分布的 excess kurtosis = 0)
| 峰度值 | 含义 | 特征 |
|---|---|---|
| = 0 | 中峰(Mesokurtic) | 与正态分布相似 |
| > 0 | 尖峰(Leptokurtic) | 尾部更厚,更多极端值 |
| < 0 | 平峰(Platykurtic) | 尾部更薄,极端值更少 |
峰的个数¶
- Unimodal(单峰):一个众数,最常见的分布形态
- Bimodal(双峰):两个众数,可能暗示数据来自两个不同的子群体
- Multimodal(多峰):多个众数
1.4 常见概率分布¶
| 分布 | 类型 | 公式/参数 | 应用场景 |
|---|---|---|---|
| 正态分布 | 连续 | \(f(x) = \frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\) | 自然界普遍现象 |
| t 分布 | 连续 | 自由度 \(df\) | 小样本均值检验 |
| F 分布 | 连续 | \(df_1, df_2\) | 方差分析 |
| 卡方分布 | 连续 | 自由度 \(k\) | 独立性检验 |
| 伯努利分布 | 离散 | \(P(X=1)=p\) | 二值结果 |
| 泊松分布 | 离散 | \(\lambda\) | 单位时间内事件次数 |
中心极限定理(CLT)
无论总体分布如何,当样本量 \(n\) 足够大时(通常 \(n \geq 30\)),样本均值的分布趋近于正态分布: $\(\bar{X} \sim N\left(\mu, \frac{\sigma^2}{n}\right)\)$ 这是许多统计推断方法的理论基础。
2. Bivariate Statistics - Correlation ¶
2.1 相关性分析¶
相关性分析用于描述 两个变量之间 的线性或单调关系强度。
Pearson's r — 皮尔逊相关系数¶
衡量两个连续变量之间的 线性关系:
取值范围 \([-1, 1]\):
| \(r\) 的范围 | 相关强度 |
|---|---|
| $0.7 \leq | r |
| $0.4 \leq | r |
| $0.2 \leq | r |
| $0.0 \leq | r |

Spearman's rho — 斯皮尔曼相关系数¶
衡量两个变量之间的 单调关系(不要求线性),基于秩次(rank)计算:
其中 \(d_i\) 是两个变量对应值的秩次之差。
Pearson vs Spearman
- Pearson:衡量线性关系,要求数据近似正态分布,对异常值敏感
- Spearman:衡量单调关系,不要求正态分布,对异常值鲁棒
- 当关系是单调但非线性时(如指数关系),Spearman 可能更合适
2.2 Correlation vs Causation¶
相关性不等于因果关系。这是数据分析中最常见的陷阱之一。
例如:冰淇淋销量与溺水事件数量呈正相关,但这并不意味着冰淇淋导致溺水——两者都受 混杂变量(confounding variable) "气温"的影响。
要确立因果关系,通常需要:
- 随机对照实验(RCT):金标准
- 时间先后性:原因发生在结果之前
- 排除混杂变量:控制其他可能的影响因素
- 剂量-反应关系:原因的强度与结果的强度成正比
3. Data Visualization ¶
选择合适的可视化方式是有效传达数据信息的关键。
| 图表类型 | 适用数据 | 用途 |
|---|---|---|
| Bar Graph(条形图) | 分类数据 | 比较不同类别的数量 |
| Histogram(直方图) | 连续数据 | 展示数据分布形状 |
| Pie Chart(饼图) | 分类数据 | 展示占比关系 |
| Box Plot(箱线图) | 连续数据 | 展示分布和异常值 |
| Violin Plot(小提琴图) | 连续数据 | 结合箱线图和密度图 |
| Line Plot(折线图) | 时间序列 | 展示趋势变化 |
| Area Plot(面积图) | 时间序列 | 展示累积量变化 |
| Stacked Area Plot | 时间序列 | 展示各部分占比变化 |
| Bubble Plot(气泡图) | 三变量 | 用气泡大小表示第三维 |
| Heatmap(热力图) | 双变量 | 展示相关性矩阵 |
| Radar Chart(雷达图) | 多变量 | 多维度综合比较 |
可视化最佳实践
- 选择与数据类型匹配的图表
- 坐标轴要有清晰的标签和单位
- 避免使用 3D 图表——它会扭曲数据感知
- 饼图类别不宜超过 5-6 个
- 颜色要有意义,不要随意使用